Ebben a cikkben az adatközpontok hálózati paradigma váltásának a technológiája kerül bemutatásra; azaz az út, amely a hálózat központú infrastruktúrától az alkalmazás központú infrastruktúráig vezetett.
DC hálózati evolúció és a Cisco ACI - út a hálózatközpontú architektúrától az applikáció központú megoldásig

A 21. század elejére tehető az adatközpontok virtualizációs forradalma. A virtuális gépek (VM) használatával optimálisan lehet alkalmazni a hardver infrastruktúrát, ezért a fizikai szerverek száma csökkent, de az egyes kiszolgálók CPU, RAM igénye növekedett. Az hálózati interfészek sávszélessége is gyorsan emelkedett, így hamar eljutottunk az 1 Gbps sebességről a 10, 25, 40, 100, 200 vagy akár a 400 Gbps átvitelig.
Az alábbi felsorolásban összefoglalom, hogy a virtuálizációs forradalom milyen további következményekkel járt:
- A nagy sebességű SFP csatlakozók jóval drágábbak, mint az 1 - 10Gbps átvitelt biztosító RJ45 megfelelőik, ezért tarthatatlanná vált, hogy a STP protokoll blokkolja a sávszélesség felét.
- A virtualizáció lehetővé teszi a VM-ek gyors mozgatását, de az IP és átjáró beállításaik ettől még nem változhatnak meg.
- A virtualizált környezetben egy hardveren egymástól elkülönítve több ügyfél szerverei futhatók, de így egy nagyobb DC-ben négyezer VLAN nem elegendő.
- A virtuális gépek és később a konténerek megjelenésével az adatközpontok forgalmának nagy része nem hagyja el a hálózatot (észak – dél irány), hanem a DC-n belül marad (kelet – nyugat irány), viszont a több ügyfeles környezetben erre a forgalomra is szeretnénk biztonsági és hálózati házirendet érvényesíteni. A tűzfalak a hagyományos topológiánál a hálózat határán, azaz a kijáratánál helyezkednek el, ezért a házirendek érvényesítése a K-Ny forgalom esetén, a hagyományos parancssori felület (CLI) használatával egyfajta rémálommá vált.
- A VM-ek egy része nemcsak az privát DC-ben, hanem felhőben is futtatható és szeretnénk, ha ezekre a VM-ekre ugyanolyan házirend vonatkozna, mint a helyben futtatott társaikra.
- A szerver virtualizáció egy új hálózati réteget hozott létre, ami a hardver kiszolgálókon belül fut, Vmware esetén ez a Distributed Virtual Switch (DVS). Ezt a hálózati réteget nem a hálózati, hanem a szerver csapat konfigurálja, ami ellentmondásos házirendekhez vezethet.
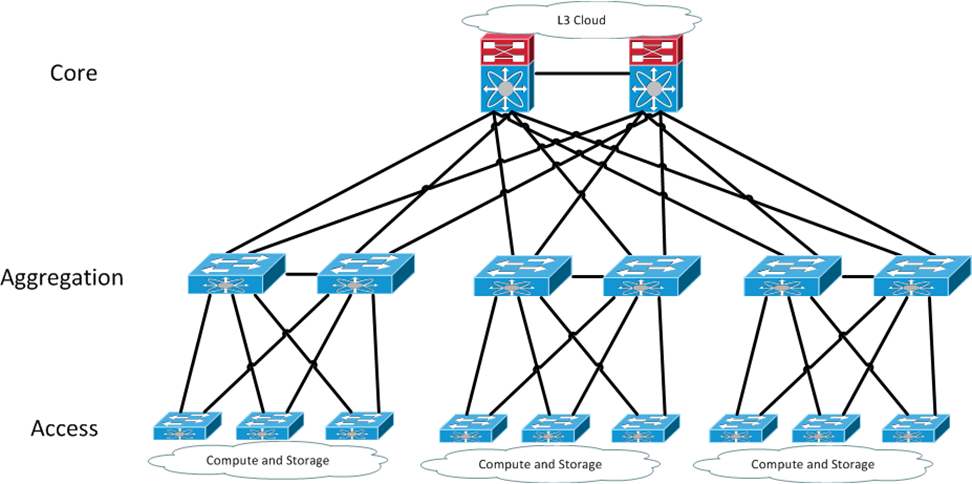
A Cisco Nexus adatközponti switchek olyan képességekkel és technológiákkal adtak választ a felsorolt követkeményekre mint a vPC, a VRF, a VN-TAG és a VXLAN, de ezek a fenti kihívásoknak csak egy-egy elemét kezelték, így nem voltak teljesen kielégítőek. Közös hátrányuk az, hogy továbbra is az 1. ábrán látható hagyományos, hálózat központú infrastruktúrát feltételeztek.
1. ábra
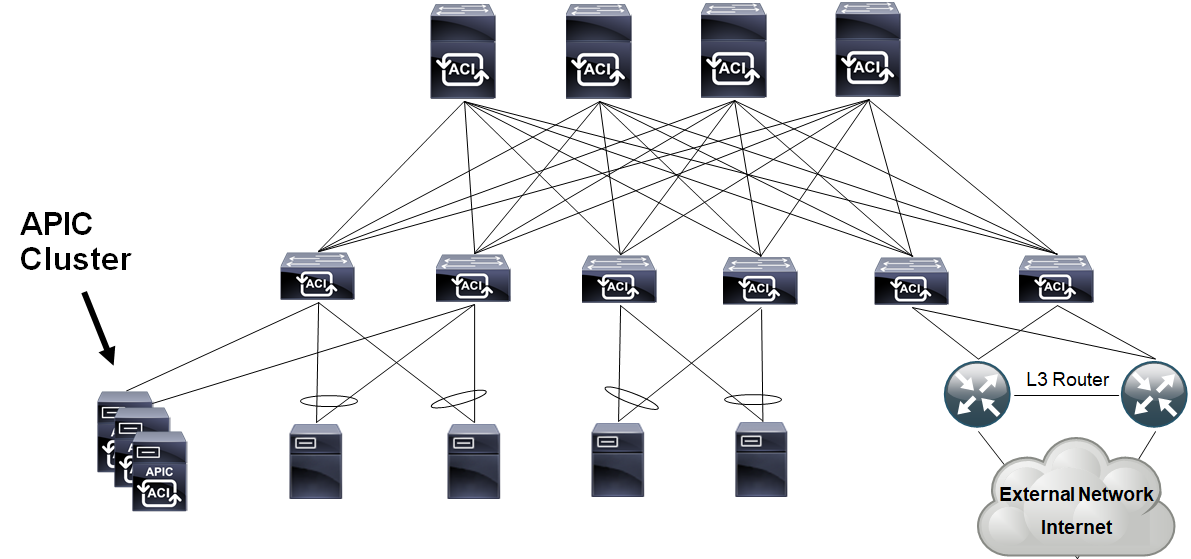
Ezzel szemben a Cisco Application Centric Infrastructure (ACI) teljesen megújítja azt, amit eddig a hálózatokról tudtunk, a topológiától kezdve a csomagtovábbítás elvein át, a hálózat konfigurálásáig – minden megváltozik. Egy tipikus ACI hálózat a 2. ábrán látható.
2. ábra
Az ACI topológia egy kétszintű úgynevezett Clos hálózat: a szervereket kiszolgáló Leaf switcheket az egymáshoz nem kapcsolódó Spine switchek kötik össze. A gyakorlatban ezt úgy kell elképzelni, hogy az adatközpont minden Rack szekrényébe két Leaf eszközt telepítünk, amik redundáns hálózati kapcsolatot biztosítanak szekrényben levő szerverek részére. A Leaf-ek így a hagyományos Top of the Rack (ToR) eszközök szerepét töltik be. A Spine switchek a hagyományos End of the Row (EoR) eszközök és a hálózati gerinc funkcióját biztosítják. Ha több hálózati végpontra van szükség akkor újabb Leaf switcheket helyezünk üzembe, ha pedig a sávszélességet szeretnénk növelni, akkor több Spine eszközt telepítünk. A hagyományos, hálózat központú infrastruktúra esetén ennek a felépítésnek az a hátránya, hogy minden eszközt külön kell konfigurálni és nincs központi management. Az ACI viszont nem konfigurálható a megszokott CLI felületen, helyette az Application Policy Infrastructure Controller (APIC) kontroller fürt végzi a hálózat menedzsmentet, amit WEB felületen, vagy REST API interfészen keresztül érhetünk el. Ezzel elkerülhető a CLI rémálom és a hálózat konfigurációja mindig konzisztens marad.
Az ACI underlay hálózat egy VXLAN Fabric, ami IP-be csomagol minden üzenetet, így nincs szükség a Spanning-Tree protokollra ráadásul automatikusan ECLB terheléselosztással jár. A Leaf kapcsolókon ugyanazon az Anycast IP címen megszólítható SVI interfészeket konfigurálhatunk, ezért egy VM mozgatása miatt nem kell megváltoztatni az IP címét vagy az alapértelmezett átjárót – ugyanabban az L2 hálózatban találja magát a mozgatás után is. Mivel az egyes alkalmazások Ethernet üzeneteit IP protokollba csomagolva továbbítjuk a Leaf-ek között ezért mind az L2 mind az L3 csomagtovábbítás algoritmusa és táblázatai teljesen mások, mint amit eddig megszoktunk és használtunk. Az ACI esetén a TCP/IP rétegmodellben egy új, eddig nem használt Link réteget vezetünk be, aminek ismerete kritikus jelentőséggel bír a hálózat konfigurálása, üzemeltetése és hibakeresése során.
3. ábra
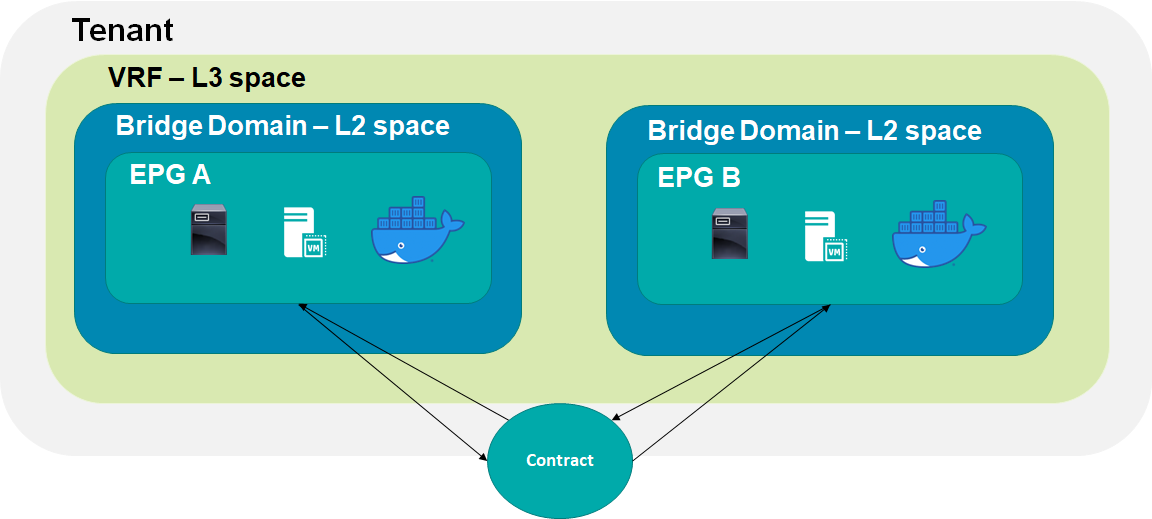
Az ACI hálózati házirendet a 3. ábrán látható Application Policy Model (APM) segítségével fogalmazhatjuk meg. Egy ügyfél eszközeit a részére definiált tenant kezeli, de még egy tenant-en belül is lehet a forgalmat egymástól elkülönítő Virtual Routing and Forwarding (VRF) példányokat létrehozni. Egy VRF-en belül definiált L2 hálózatot – leánykori nevén VLAN – Bridge Domain-nek (BD) hívjuk. A BD az ACI rendszer bármelyik Leaf switchén bármelyik VLAN tartalmazhatja, így a VLAN-oknak az ACI rendszerben csak lokális jelentősége van, minden Leaf eszközön a teljes VLAN tartomány újra felhasználható.
A hálózati házirend alapegysége az End Point Group (EPG). Az EPG-n belül minden forgalom engedélyezett, de EPG-k között csak olyan csomagokat továbbít a Fabric, amit Contract-nak hívott házirenddel engedélyezünk. Két EPG között létrehozott Contract minden esetben érvényre jut, még akkor is, ha a kommunikáló alkalmazások azonos L2 hálózatban azaz BD-ben vannak. A Contract szabályrendszere egy hagyományos ACL-re hasonlít, de a Service Graph és Policy Based Redirect objektumok segítségével a házirend még jobban testre szabható, mert így bizonyos csomagokat két EPG között közvetlenül továbbíthatunk, de szükség szerint eltéríthetjük őket és az ACI-tól független, akár virtuális terhelés elosztónak vagy tűzfalnak adhatjuk át.
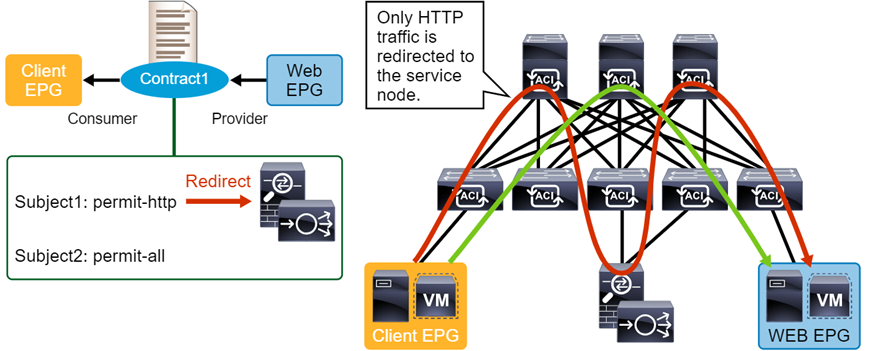
4. ábra
A 4. ábrán egy ilyen átirányításra látunk példát. A Client EPG és a Web EPG között létrehozott Contract második szabálya minden forgalmat engedélyez, de az első szabály a HTTP csomagokat eltéríti és egy tűzfal, illetve terheléselosztó felé továbbítja.
Az APM lehetővé teszi, hogy a Fabric érvényre juttassa a hálózati házirendet, az É-D irányú forgalmat szűrő központi tűzfal használata nélkül és biztosítja, hogy a szerverek között mozgó VM-ekre mindig ugyanaz a hálózati házirend vonatkozzon egészen addig, amíg nem változik az EPG tagságuk.
Az ACI Fabric AWS, és Azure felhővel vagy VMware, KVM, Hyper-V, Kubernetes és OpenShift helyi virtuális környezettel is integrálható, így a házirend az itt futó VM-ekre is érvényesíthető, azaz a virtualizált környezeten belül is a hálózati csapat által definiált szabályok automatikusan érvényre jutnak. Ezeket a lehetőségeket foglalja össze az 5. ábra.
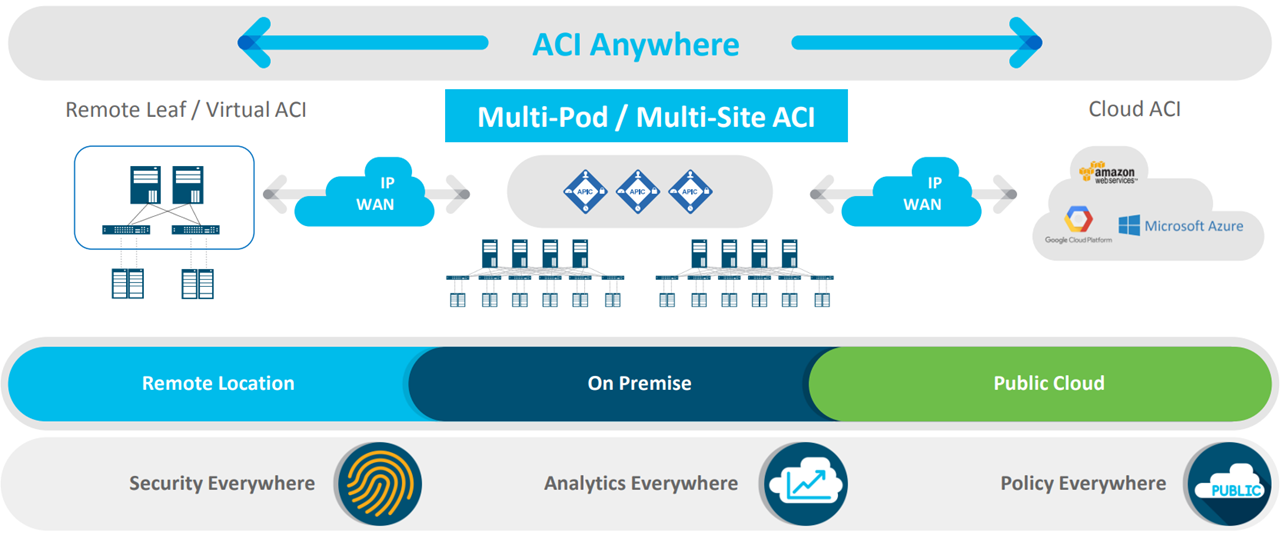
5. ábra
Összefoglalás: az ACI megoldást jelent az adatközpontok virtualizációjával járó és fent ismertetett összes problémára:
- nincs szükség STP protokollra,
- a VM szabadon mozgatható a Fabric-ban, nem változnak az IP beállításai,
- a VXLAN 16 millió BD-t kezel szemben a négyezer VLAN-nal,
- a hálózati házirendek az egész Fabric-ban és a virtualizációs hálózati rétegben is érvényre juttathatók,
- a hálózatot egy központi kontroller konfigurálja,
- a rendszer kiterjeszthető a felhő szolgáltatóknál futó VM-ekre is.
Szeretnél többet tudni?
Vedd fel velünk a kapcsolatot az alábbi elérhetőségen:
- Gőgös Barnabás
Senior Systems Engineer
+36 30 162 0841
barnabas.gogos@alef.com