Přizpůsobitelné architektury v AWS

AWS cloud si lze představit jako lego stavebnici. Na základní stavební desce VPC skládáme dohromady nejmenší dílky, například VMs v různých barvách jako EC2/Serverless/K8s, dokud nemáme dostavenou celou aplikaci. AWS nabízí různé stavebnicové sady, například sadu pro ukládání objektů a sadu pro zpracování streamu, které můžeme sestavit samostatně nebo namíchat s dalšími stavebnicemi.

V tomto článku se podíváme na některé přizpůsobitelné architektury, které můžete zahrnout ve vaší další aplikaci.
Architektury v tomto článku:
- Ukládání objektů
- Zpracování streamu
- Autentizace poskytovatelem identit
- Rozesílání zpráv
- Caching
Ukládání objektů:
Protože ukládání objektů do databází je nákladné, častým způsobem ukládání objektů v AWS je užitím služby AWS S3. Protože AWS S3 nemá definované schéma, chceme-li se v datech vyznat a najít co potřebujeme, je potřeba uložit metadata o jejich umístění do databáze.
Diagram níže znázorňuje obecnou strukturu tohoto řešení:
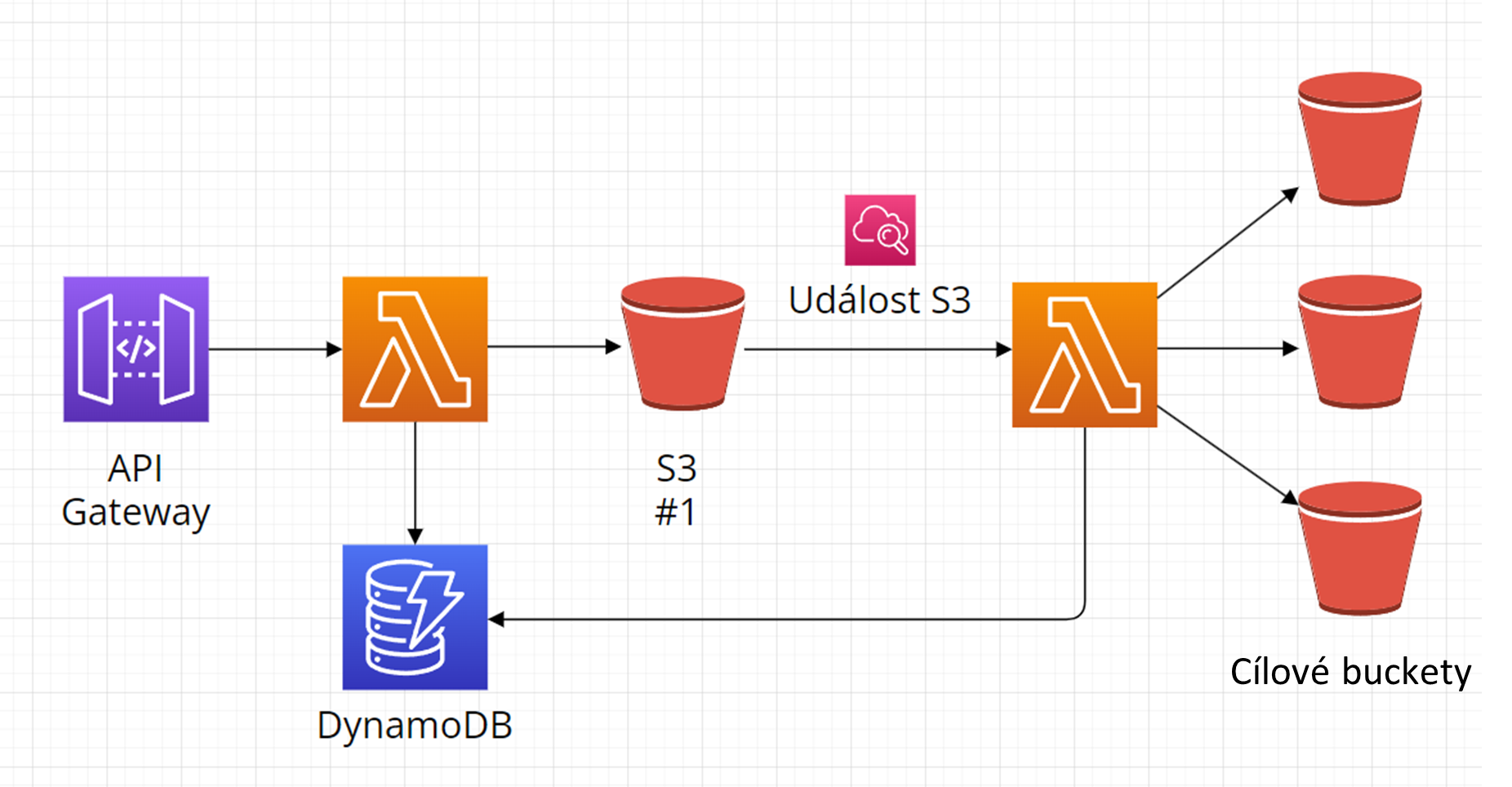
Ukládání
- API call na uložení obrázku zavolá AWS Lambda funkci
- AWS Lambda funkce vloží obrázek do S3 Bucketu #1
- S3 Event spustí navazující AWS Lambda funkci, která obrázek vloží do cílového S3 Bucketu a současně metadata s informací o umístění vloží do DynamoDB databáze.
Získávání
- API call na načtení obrázku zavolá AWS Lambda funkci
- AWS Lambda funkce získá umístění obrázku jednoduchým dotazem do DynamoDB databáze a vrátí URL s adresou daného obrázku v S3 Bucketu.
S metadaty můžeme ale pracovat i dále a využít je pro další funkce a služby. Například můžeme metadata o umístění za pomocí AWS Lambda funkce předat službě AWS Rekognition, která je může dále obohatit o další informace. Například označení „nevhodný obsah“ a ty přidat zpět do databáze metadat uložených, jak je znázorněno na následujícím diagramu:
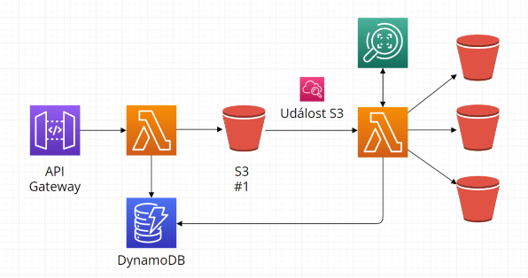
Zpracování streamu a zobrazení výsledků:
Potřebujeme-li zpracovávat od uživatelů a producentů dat kontinuálně příchozí data (nepřetržitá data), využívá se služba AWS Kinesis. AWS Kinesis je služba pro shromažďování, zpracovávání a analyzování streamu dat v reálném čase.
Proces zpracování streamu takovýchto dat má 4 kroky:
- Získání dat
- Transformace dat, pokud schéma nevyhovuje aplikaci (volitelná)
- Získání výsledků
- Zobrazení výsledků
1. Získání dat (a odesílání ke zpracování)
Služba AWS Kinesis nám poskytuje ke zpracování streamu několik různých služeb, které se hodí pro různé aplikace.
Existuje-li nějaká pipeline, kam data na posílat, využívá se služba AWS Kinesis Data Streams. Zdrojem mohou být například video či audio soubory, logy nebo click-stream z obrazovky a další.
Diagram níže zobrazuje získání logů pomocí subskripce a jejich odeslání do pipeline pomocí AWS Kinesis Data Streams:
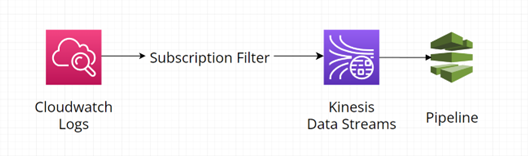
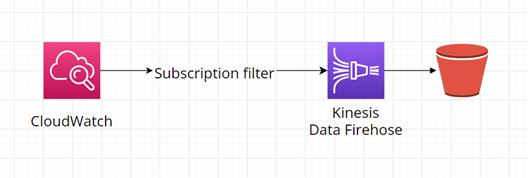
Potřebujeme-li ukládat data ze streamu do úložiště k pozdějšímu zpracování, využívá se AWS Kinesis Data Firehose. Zdrojem může být například služba AWS SES, IoT senzor, server/aplikace která generuje logy, AWS CloudWatch nebo třeba AWS EventBridge. Destinací pro tato data pak mohou být jak souborové systémy/služby (například AWS S3, AWS ESB), tak databáze (například AWS Redshift, MongoDB) nebo další cíle (například http endpoint nebo OpenSearch).
Diagram níže znázorňuje příklad sběru logů pomocí AWS Kinesis Data Firehose a jejich uložení do služby AWS S3:
AWS Kinesis Data Streams a AWS Kinesis Data Firehose můžeme samozřejmě i kombinovat. Jako příklad si vezměme následující diagram. V této ukázce kontejnerizované aplikace a AWS Lambda funkce zpracovávají/upravují stream dat z AWS Kinesis Data Streams, který poté pokračuje do AWS Kinesis Data Firehose k uložení do cílového S3 Bucketu:
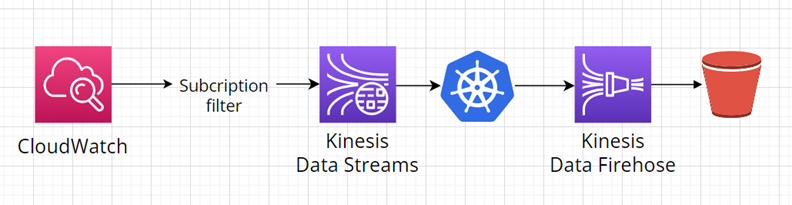
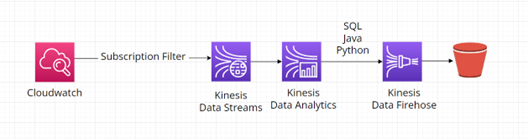
Stream lze také dále zpracovávat/analyzovat například za pomoci AWS Kinesis Data Analytics. Výhodou tohoto řešení je že nezahrnuje potřebu spravovat více zdrojů. Diagram níže znázorňuje užití všech AWS Kinesis služeb dohromady. Stream dat z AWS Kinesis Data Streams je zpracováván pomocí AWS Kinesis Data Analytics, poté pokračuje do AWS Kinesis Data Firehose k uložení do cílového S3 Bucketu:
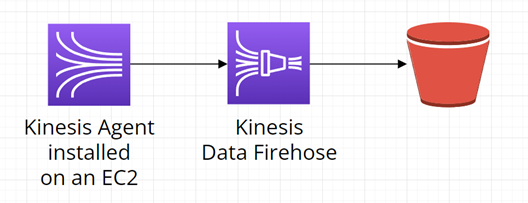
Data samotná můžeme posílat do služby AWS Kinesis několika způsoby, například pomocí Kinesis Agent nebo KPL, PutRecord/s nebo Subcription Filter. Následující diagram znázorňuje řešení užitím Kinesis Agent nainstalovaném na EC2. Kinesis Agent sbírá a odesílá data do AWS Kinesis Data Firehose k uložení do cílového S3 Bucketu:
2. Transformace (volitelná) a uložení dat
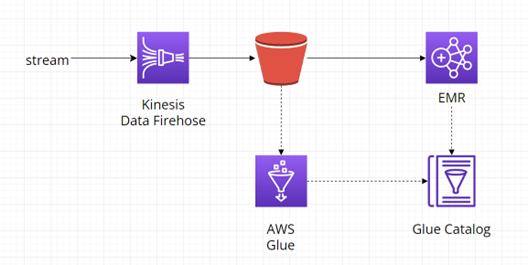
Chceme-li zobrazit výsledky streamu a vyznat se v nich, musíme mít k sbíraným datům i metadata. Některé služby, například služba AWS S3 nadefinovaná schéma ani příslušná metadata nemají. Můžeme je ale vytvořit či změnit pomocí služby AWS Glue. AWS Glue lze kromě služby S3 také připojit k AWS Redshift, RDS, databázi na EC2 a dalším zdrojům, jak lze vidět na diagramu níže:
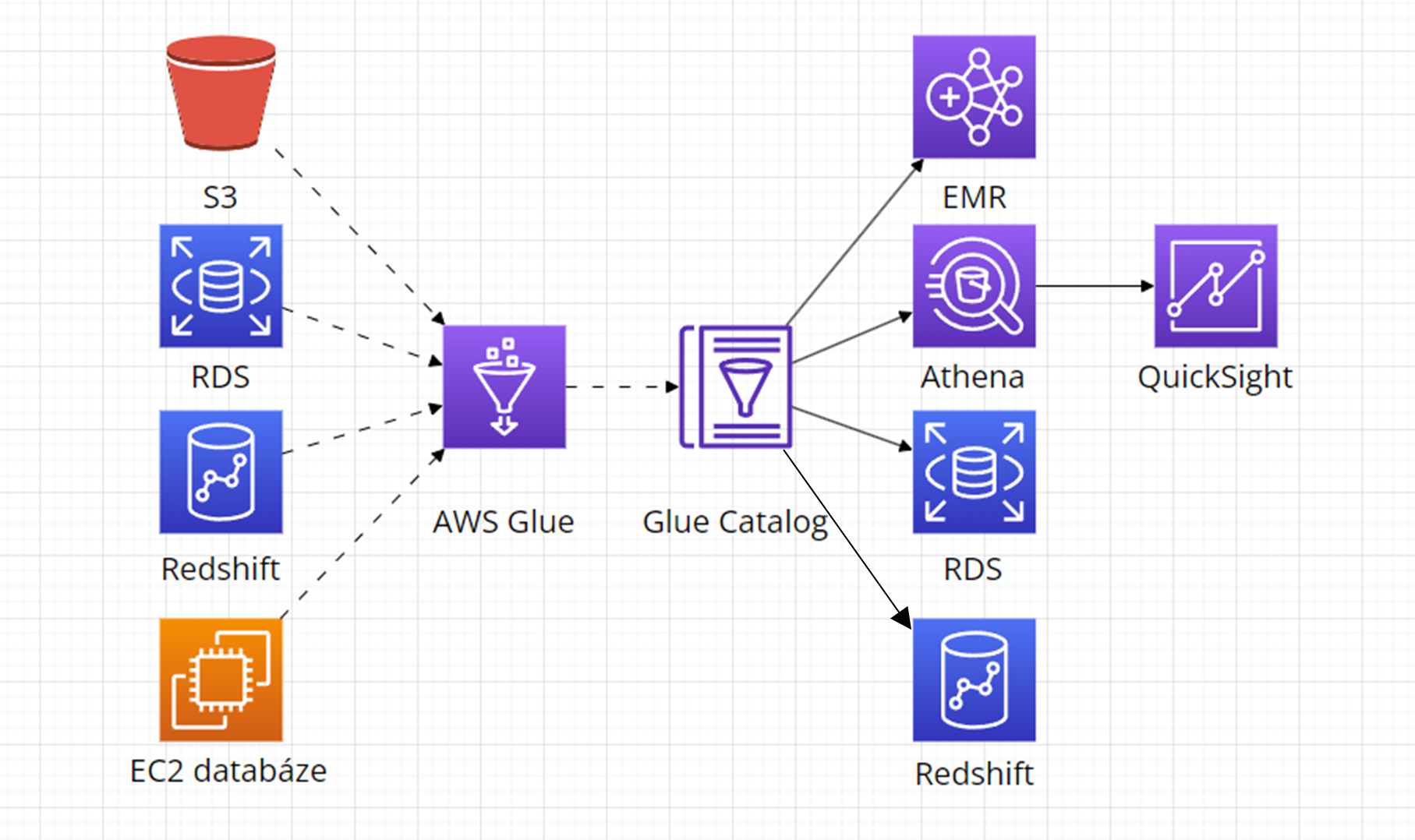
3. Získání výsledků
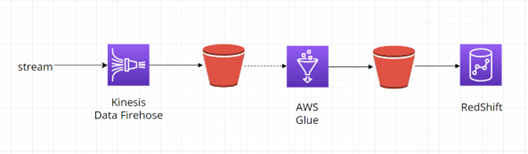
Sesbíraná data, která jsou nyní uložena v S3 Bucketu je nyní možné zpracovávat. Diagram níže znázorňuje příklad získání výsledků pomocí služby AWS Redshift. Toto řešení se hodí například pro skladování dat:
 Dalším možným způsobem zpracovávání je pomocí služby AWS Athena, jak je vidět na následujícím diagramu. Výhodou služby AWS Athena je že není potřeba spravovat žádnou infrastrukturu:
Dalším možným způsobem zpracovávání je pomocí služby AWS Athena, jak je vidět na následujícím diagramu. Výhodou služby AWS Athena je že není potřeba spravovat žádnou infrastrukturu:
4. Zobrazení výsledků
Posledním krokem je zobrazení zpracovaných výsledků.
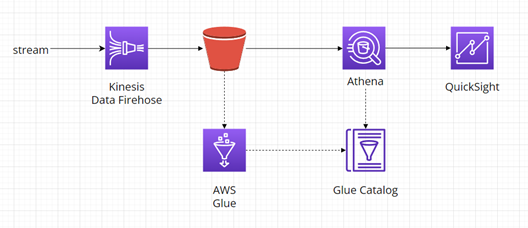
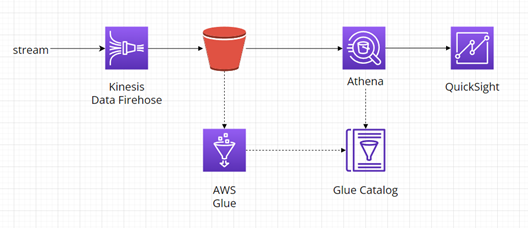
Diagram níže zobrazuje čtení dat z AWS S3 za pomocí AWS Athena s vytvořeným Glue katalogem a následné zobrazení výsledků pomocí AWS Quicksight:
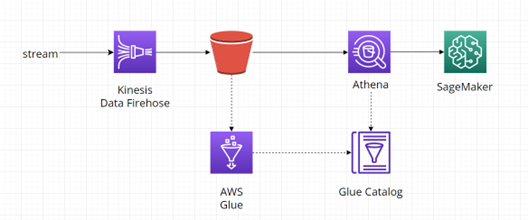
Další možností je například zpracování dat pomocí AI, kdy je princip stejný jako u přechozího příkladu, ale cílovou službou je AWS SageMaker:
Pokud potřebuje zpracovat masivní objem dat, nabízí se možnost využít napřímo službu AWS EMR:
Autentizace poskytovatelem identit (IdP):
Pokud v aplikaci potřebujeme udělit přístup ke zdrojům pouze ověřeným externím uživatelům, AWS poskytuje hned několik služeb které nám mohou pomoci. AWS Cognito User pool, Simple AD, AD Connector i AWS Directory Service pro Microsoft AD jsou poskytovatelé identit, kteří mohou být použity k uchování informací o uživatelích a udělení přístupu.
Diagram níže zobrazuje obecnou strukturu autentizace:
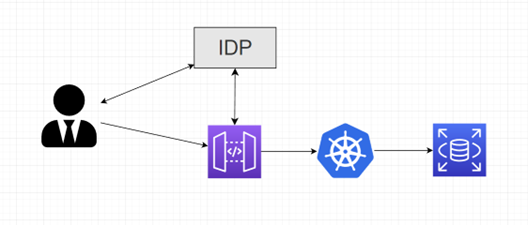
- Uživatel vyplní přihlašovací údaje, údaje jsou odeslány do IdP
- Pokud přihlašovací údaje souhlasí, IdP odešle uživateli zpět autentizační token
- Uživatel odešle ID a autentizační token do AWS API Gateway
- AWS API Gateway ověří ID a autentizační token s IdP
- Pokud dvojice souhlasí, uživatel je přihlášen
- (Možnost nakonfigurovat caching pro autentizační token)
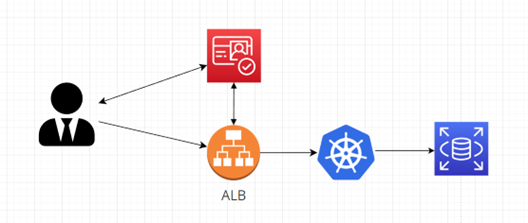
Různé poskytovatele identit lze nakombinovat s různými prezentačními službami. Následující diagram zobrazuje autentizaci pomocí služby AWS Cognito a AWS ALB:
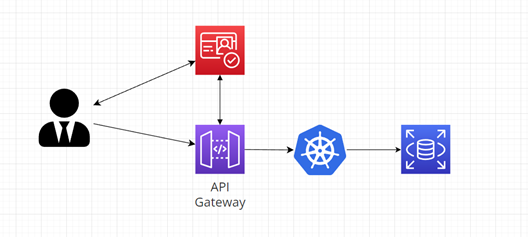
Poskytovatele identit lze dále nakombinovat například s AWS API Gateway:
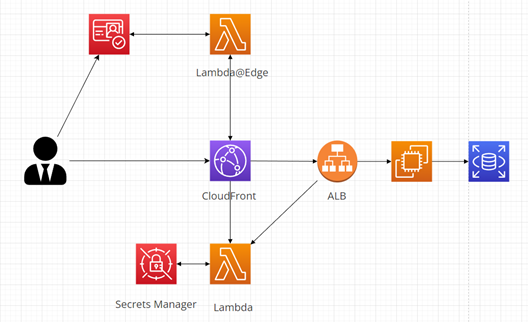
Pokud potřebujeme ještě silnější zabezpečení, autentizační Token může být uchováván v AWS Secrets Manager. Diagram níže zobrazuje ukázkovou autentizaci pomocí AWS Secrets Manager, AWS Cognito a CloudFront s Lambda@Edge:
Rozesílání zpráv:
V cloudových aplikacích často potřebujeme, aby spolu jednotlivé části aplikace mohli komunikovat a vyměňovat si informace. AWS proto poskytuje několik služeb pro rozesílání dat/zpráv.
Pro odesílání zpráv/dat ke zpracování jednomu příjemci se využívá služba AWS SQS. Užitím AWS SQS aplikace docílí asynchronnosti a zprávy budou uchovány i pokud v tu chvíli nemohou být zpracovány.
Diagram níže zobrazuje obecnou strukturu tohoto řešení, které má uplatnění například ve spoustě chatovacích aplikací:
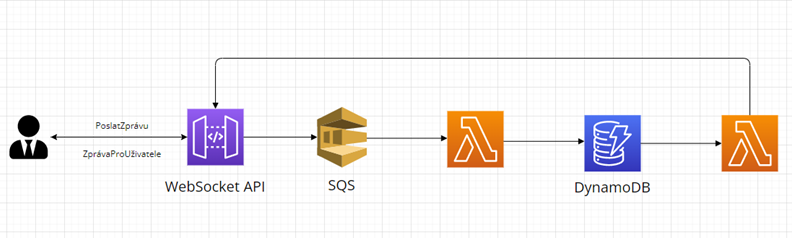
- Uživatel odešle zprávu
- AWS SQS rozdělí aplikaci
- AWS Lambda funkce si získá zprávu a vloží ji do databáze
- Druhá AWS Lambda funkce reaguje na vložení, zprávu si získá a odešle příjemci
Pokud potřebujeme, aby zprávy/data byly odesílány několika různým příjemcům, využívá se služba AWS SNS nebo AWS EventBridge.
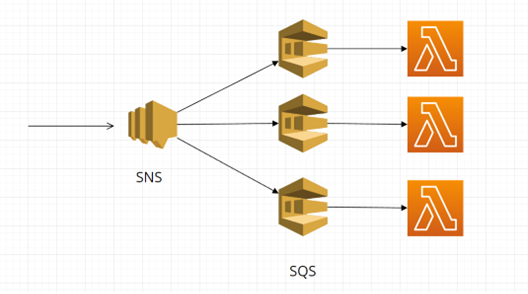
Často se využívá kombinace AWS SNS pro odesílání dat více příjemcům s AWS SQS pro zabránění ztrátě, jak je znázorněno na digramu níže:
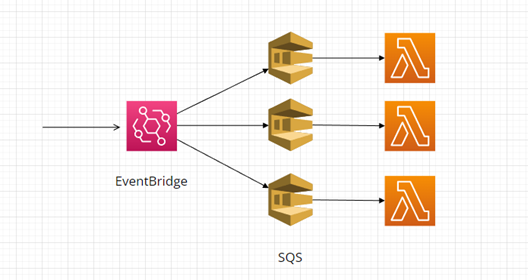
Podobně lze nakombinovat i AWS EventBridge a AWS SQS:
Caching:
Pokud potřebujeme zrychlit proces získávání dat z databáze a snížit provoz který ji zatěžuje, můžeme použít caching. V AWS se pro rychlé úložiště dat v paměti využívá služba AWS Elasticache.
Diagram níže zobrazuje obecnou strukturu:
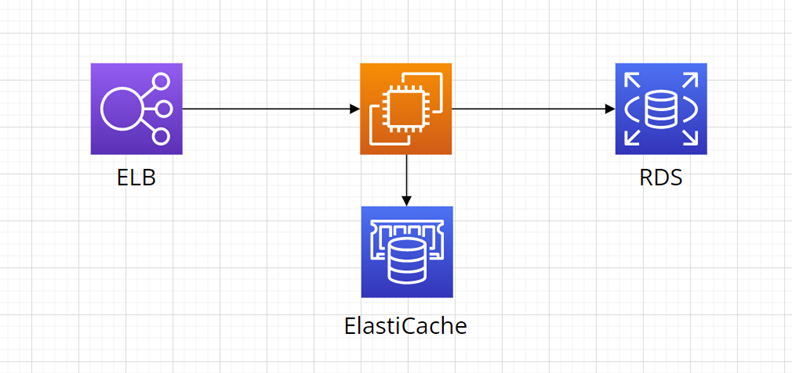
- VM nejprve prohledá AWS ElastiCache, jestli obsahuje cílová data
- Pokud data neobsahuje, VM získá data z databáze a zapíše je do AWS ElastiCache
Caching zle kromě databáze implementovat také na dalších místech v aplikaci. Diagram níže zobrazuje vzorovou aplikaci, kde všechny služby využívají nativní caching:
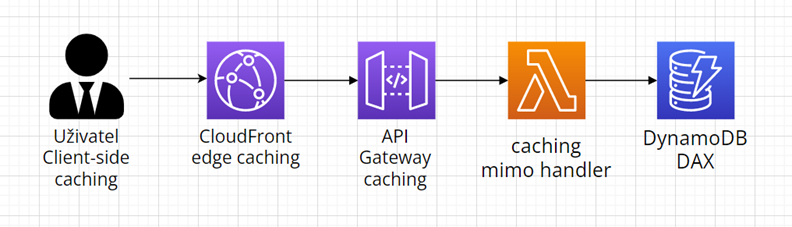
- Pomocí AWS CloudFront nativní caching lze zvýšit počet objektů uložených blíže vašich uživatelů
- Služba AWS API Gateway podporuje nativní caching pro specifické dotazy a metody
- AWS Lambda funkce lze nakonfigurovat tak, aby data mezi invokacemi zůstala uložena v mezipaměti
- Užitím DynamoDB DAX lze až 10x zvýšit výkon databáze
Obecně platí:
- Čím blíže je cache implementován ke koncovému uživateli, tím lépe.
- Pokud služba podporuje nativní caching, bývá vhodnější než AWS ElastiCache.
Další užitečné architektury:
AWS dnes poskytuje více než 200 různých služeb. Na stránkách AWS Solutions můžete procházet další ukázkové architektury a filtrovat je pomocí služeb a případu užití. Společně jsme se na některé takové podívali a ukázali si, kdy je implementovat.