Kdy dává deduplikace smysl a jak vybrat řešení, které nejlépe vyhovuje Vašim požadavkům?
3 věci, které musíte zvážit před deduplikací dat

Málokdo si dnes ještě vzpomene, že první pevné disky z 50. let minulého století měly kapacitu pouze několik megabytů, ale přitom byly větší než dnešní chladničky. Na evoluci disků je vidět, jak kapacita úložních zařízení roste, a ceny klesají. Mimořádně rychle se však zvětšuje i objem dat, která vytváříme a sdílíme.
Navíc v IT systémech se z různých důvodů hromadí duplicitní data (například objemné přílohy e-mailů rozposlané všem kolegům), které na discích zbytečně zabírají místo. Pokud firmy nevyužívají úložná zařízení efektivně, musejí do nich nejednou investovat více, než je nevyhnutelně nutné.
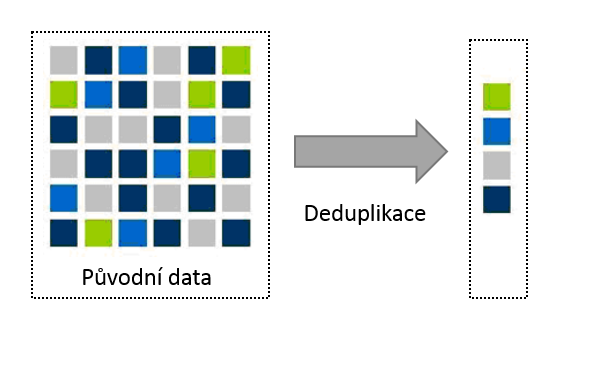
Pomocnou ruku může v těchto případech podat takzvaná deduplikace, známá také jako inteligentní komprese. Zjednodušeně řečeno – jde o odstraňování kopií identických bloků dat a jejich nahrazování jednoduchými odkazy do jediného bloku.
Cílem a přínosem deduplikace je:
- ušetření diskového prostoru,
- snížení zátěže sítě při přenosu dat,
- zkrácení doby zálohování a obnovy.
Deduplikace dat není novinka, v posledních letech však prošla změnami a dozrála. Dnes poskytuje deduplikaci prakticky každý výrobce diskových polí a zálohovacích řešení. Jednotlivé algoritmy jsou však odlišné a není lhostejné, který z nich si vyberete. Je potřeba pečlivě zvážit, kde ve Vaší IT infrastruktuře mají deduplikace smysl, a vybrat řešení, které bude nejlépe vyhovovat Vašim požadavkům.
Detailů, ke kterým je dobré při výběru vhodného řešení přihlížet, je velké množství, ale bez uvážení následujících tří kritérií optimální volbu jistě nenajdete.
- Zvažte, máte-li vhodný typ dat
Deduplikace je náročná na množství paměti a výpočetní výkon, pokud spočívá v porovnávání velkého množství datových bloků. Určitá data, například videostreamy, ani jakákoli komprimovaná data nejsou pro deduplikaci vhodná, protože systému se nepovede najít dostatek stejných bloků.
Obecně má deduplikace smysl, pokud se při hledání stejných bloků podaří dosáhnout aspoň 50 až 60% úspěšnosti. Vhodnými typy dat k deduplikaci jsou například databáze, textové dokumenty nebo e-maily.
- Vyberte vhodný způsob deduplikace
K porovnávání dat může docházet ve chvíli, kdy se zapisují na storage (tzv. inline porovnávání bloků dat), nebo až následně po tom, co se všechna zálohují na záložní disk (tzv. post-process metoda). První způsob je náročnější na paměť a výpočetní výkon. Druhý sice spotřebuje méně systémových zdrojů, ale vyžaduje více místa na disku, protože k eliminaci duplicit dojde až po zápisu všech dat.
Jestliže chcete minimalizovat doby zálohování dat, bude pro Vás zřejmě lepší volbou zařízení s post-processovým způsobem deduplikace. Pokud potřebujete rychle replikovat deduplikovaná data na vzdálený storage mimo firmu, zdá se být nejlepší volbou inline zařízení. Výsledná volba technologie závisí vždy na několika aspektech – od požadavku na dobu zálohování po objem redundantních dat až k lokalitě a typu cílového zařízení (např. vzdálená lokalita nebo páskové zálohovací zařízení).
- Zdrojová nebo cílová
Deduplikace může probíhat v cíli, čili přímo v storage, kam putují zálohovaná data přes síť, nebo ve zdroji, tedy tam, kde vznikají (na serveru nebo na klientském zařízení). Někteří dodavatelé mají dokonce hybridní model.
Výhodou zdrojového způsobu deduplikace je kratší doba zálohování a menší objem provozu v LAN či WAN síti po dobu zálohování. Obecně je tento přístup vhodný tehdy, když nedochází denně k velkým změnám v zálohovaných datech. Častěji se však firmy rozhodují pro deduplikaci na cílovém zařízení, aby nesnižovaly odezvu serverů.

David Rusín
Datacenter konzultant
cz-netapp@alef.com